Syntax for a programming language
I spent last week working on a programming language syntax.
I tried to design a language that:
- Easy to parse and understand
- Is indentation sensitive
- Has no multi-line parentheses
- Has algebraic syntax
- Has notation for anonymous functions
- Does not predefine control flow structures
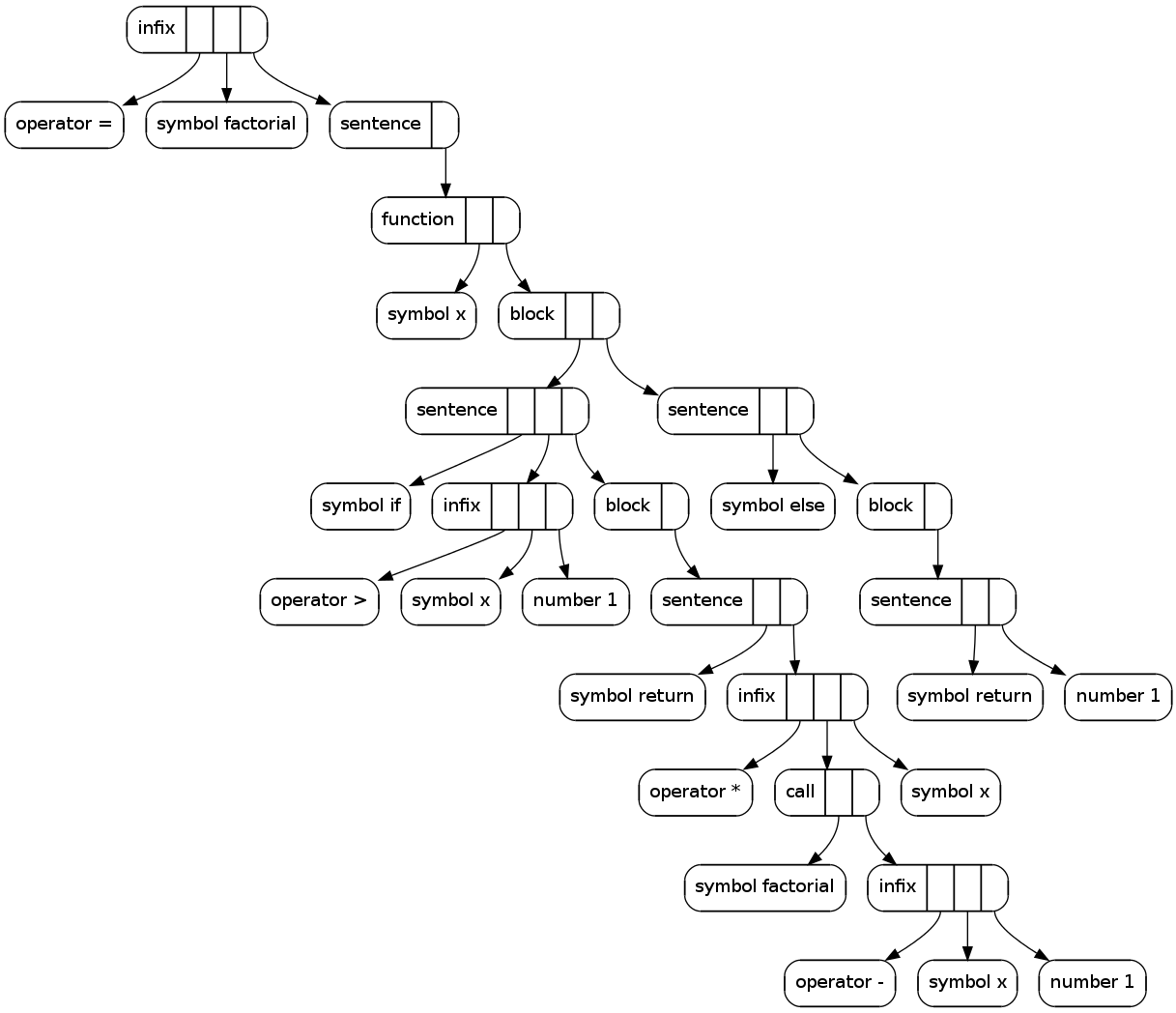
Here's a hypothetical factorial function written in that language:
factorial = (x) ->if x > 1return factorial(x-1) * xelsereturn 1
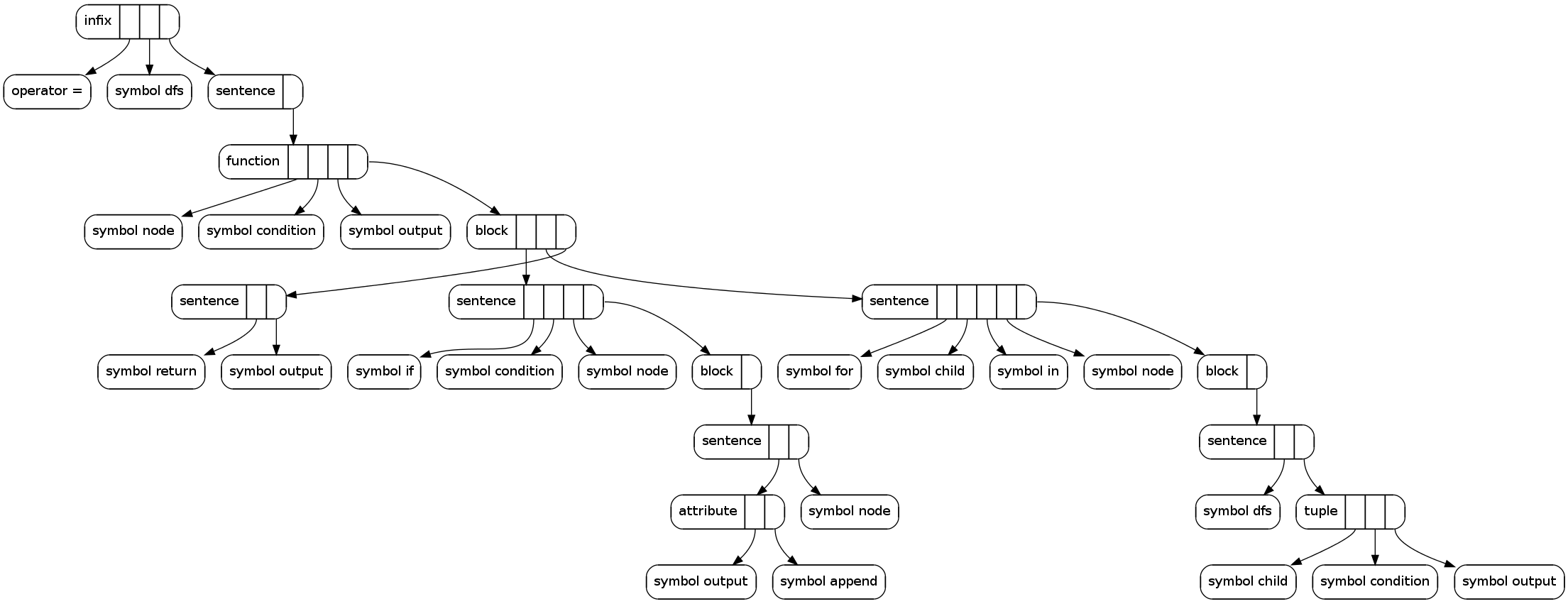
And depth first search:
dfs = (node, condition, output) ->if condition nodeoutput.append nodefor child in nodedfs child, condition, outputreturn output
This code prints the first ten elements:
print elements[0 .: 10]I hooked up graphviz to visualize outputs from the test parser. Although the parser is not complete, it is already able to parse these samples: factorial.png, dfs.png, elements.png.
{kind=link}
{kind=link}
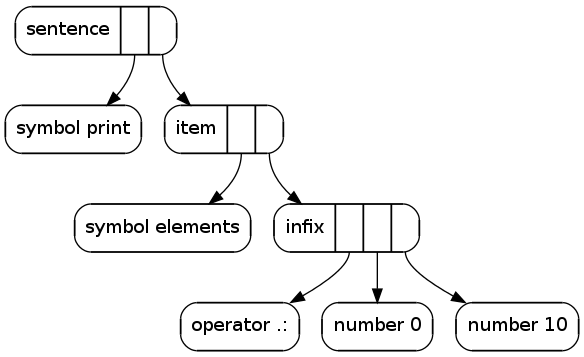
The pictures show what comes out with certain input texts. Each node has group label and it's slots drawn into it. From every slot there's an arrow to what the slot contains.
Design
The programs consist of sentences that consist of words, separated by space.
The sentences appear in blocks, formed by indentation level.
The blocks are added into end of the sentence unless there's a marker ; to denote
different organization. Sentences are only allowed on the toplevel, after a
toplevel =, or after a function header. They are never inlined. Sentence consist
of at least one word. A word can be an expression or a tuple, with expressions separated
by commas.
Infix/postfix syntax is space sensitive to avoid ambiguity in sentence-level.
For example, a - b and a-b is parsed as subtraction, but a -b is parsed as
a negation. The same rule applies for indexing a[] and list notation a [], as
well as calls a(), and tuples a ().
The first word in sentence is slightly different from the remaining.
If = or : are encountered, they capture a sentence on the right side
instead of an expression. It is supposed that equality inside function arguments
are thought as instantiation of an object rather than assignment.
Most of the syntax is familiar.
I only introduced an entirely new syntax for slices. .: and :..
As addition, you can also annotate stride with :: and skip with ...
There's fixed order for appearance of these symbols.
Stride first, skip then, such as 0 .: 10 :: 2 .. 2. This would mean that
one takes slice of [0, 10[, 2 elements at once, skip another 2.
The slice syntax is sensitive to spacing, similar to algebraic expressions.
Implementation
First input text is cut into tokens. Then they will be parsed. There's only one stage now, but there could be more. Each stage is separated from each other by a lookahead stream. They allow one looakhead before the value needs to be consumed from the stream. They also contain the most recent consumed value, for error reporting and spacing recognition.
The precedence for all infix operators are parsed inside same function. Handling rules come from a table.
Overall the parser can be hand-written entirely such that it ends up being clean and understandable. I prefer that way of implementing the parser.
Flaws and possible defects
I haven't finished the parser yet, it's missing few important parsing rules I just introduced today to solve issues with ambiguity. And I haven't tested it with a real person. It seems to be easy to create the kind of error messages that help the person to understand what went wrong though. But to be sure that it's reliable and works like I mean I have to test how people really react to this language.
On the toplevel it's very easy to do the a + b -error. I tried to give the syntax
some strictness to counter that, but I don't know how it will work. Being able to
do such "top level" calls is important to me.
Due to the way parsing is implemented, things that look similar are parsed in similar manner. That's why I didn't use the python notation for slicing. I came up with my own. Also left some other things out, ternary expressions for instance.
It is supposed to be flexible syntax. Every language which uses it can redefine
meaning of some elements and define itself how the sentence is read. It means I
can't provide same semantics as there are for in in python for example. The
sentence simply won't parse right if I do. Also, if you do something like:
while x, y =, then that won't either parse right. But then it won't even mean
the same. Overall I'm not sure whether this kind of flexibility is a good or bad thing.
I could also encode the valid sentences as data and let them to be passed to a parser.
I haven't figured out how to name this new syntax. Though that only matters if I end up creating something that is using it.