The internals of this blog need an update
Today I'm going to pull the blog guts outside and show them to the world. The blog has become slower, it takes several seconds to update, but this is not the main reason to improve it now.
I've promised I'll make a structured sitemap to make it easier to access the content on this website, this map would eventually extend to articles that cover type systems, category theory, compiler design. It would also link&describe other blogs and feature research papers whenever they have explained the content better than I have.
Another reason to upgrade would be to add in a table-of-contents for each blog post.
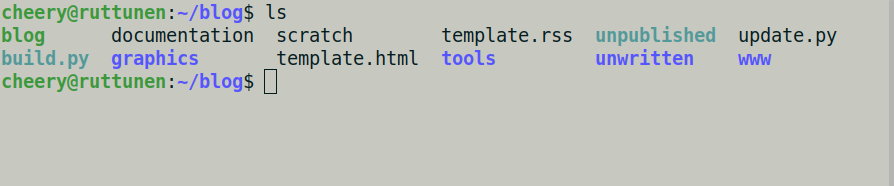
Visible structure of the blog
The first thing you see here is that it's a static blog
that sits in a filesystem, the www/ -directory
is exposed to the world.
The unpublished/ is a
symbolic link to the www/unpublished/.
The unwritten/ is a directory consisting of
unwritten material not ready for publishing.
scratch is an empty file I used as memo a long time ago.
The structure visible outside from the blog follows the format:
blog_sitemap.txt: text formatted sitemap containing a link to every post, a machine-readable version of the index.html, apparently useless and can be removed in the update.catalog/: a rarely updated directory that links to stuff I made a long time ago. I used this to showcase my web stuff. These form the blog's "appendix" and I suppose I'd like to keep them along. They hurt nobody after all, although they've become unnecessary.entries/: consists of the blog entries. It's formattedyear/month/day/postname/where the month is 3-letter lowcased month, year, day are numbers, and postname is the directory name for the post. The very first post has zero before the one-digit day01. I made a tool to update the blog shortly after that is still in use (more about this later).feed.rss, an RSS feed to help people stay updated of the new reading on the site.style/, the stylesheets for the blog, bunch of stylesheets maintained with sass.unpublished/consisting of blogposts put up for me or other people to review. All of these posts were not published.
In each blog entry, it's got the certain structure.
summary-file that has plaintext-formatted summary about the posts content for the automated mailing list to use.index.mdfor constructing theindex.html.- Each entry has a directory that may contain other supplemental content or JS scripts associated with the blogpost.
- These days there's an occassional
Makefilethat I actuate with a quick-command from my editor to preview the post contents in a browser.
Each blogposts needs to receive previous/next -post tags to update the link chain in the bottom of the pages.
Design decisions made
I did the absolute minimal effort to make this blog work. Though it was designed after a good friend's similar blog that did the same thing. I tried to minimise the amount of third party tooling to maintain it.
Later I found out the content is important and stripped down most things standing on its way. I'd guess this was partially a good decision but I overdid it and even removed some important things such as the badge. I'm planning to throw in a new badge though, with a keppel/ivory color -scheme.
Straight from the beginning I decided to not hold ad banners on the website. This was a great decision because automated online advertising is more disgusting than it has ever been and ignores users and content creators alike.
Hidden internals of the blog
Now we got some internals to check out.
I can outright tell that the graphics -directory
is barren, the documentation contains the following text:
If the blog-directory contains 'summary', it is readed asutf-8 -file that is then added into the RSS-feed.It may be used other ways too.. Not certain yet.
Templates are ordinary markup files that are parsed with beautifulsoup and then filled up with a script.
The tools/ directory contains exactly one file.
The tools/check_links.py contains the following script
that finds every link in the website and checks that it is still valid:
# This is a small script that tries every link in a list to see whether# it works.import urllib2import sysimport time# For this script to work, you have to give a file to list of links as an# argument.def main(argv):with open(argv[1], 'r') as fd:for line in fd.readlines():link = line.strip()try:ret = urllib2.urlopen(link)except urllib2.HTTPError as e:print "error{}: {}".format(e, link)continueif ret.code != 200:print "!not present ({}): {}".format(ret.code, link)else:print "ok: {}".format(link)time.sleep(0.5)if __name__=='__main__':main(sys.argv)
The build.py does a symbolic link to update.py.
The blog is a script to create a directory for the blog.
It can be run like this:
cd $(./blog today -c)cd $(./blog monday -c)
To create a blog directory for today, or the next monday and then move there. The script can be fun enough to look at so it's straight off here in whole.
#!/usr/bin/env python2import argparseimport datetimeimport errnoimport osdef main():parser = argparse.ArgumentParser(description="blog command prompt")subparsers = parser.add_subparsers()today_cmd = subparsers.add_parser('today',help="print the blog directory path for today")today_cmd.add_argument('--create', '-c', action='store_true')today_cmd.set_defaults(func=today_fn)weekdays = [(0, 'monday'),(1, 'tuesday'),(2, 'wednesday'),(3, 'thursday'),(4, 'friday'),(5, 'saturday'),(6, 'sunday') ]for index, weekday in weekdays:date_cmd = subparsers.add_parser(weekday,help="print the blog directory path for " + weekday)date_cmd.add_argument('--create', '-c', action='store_true')date_cmd.set_defaults(func=date_fn(index))args = parser.parse_args()args.func(args)def today_fn(args):today = datetime.date.today()create_date_path(args, today)def date_fn(day):def __date_fn(args):today = datetime.date.today()monday = today + datetime.timedelta(days=((day - today.weekday()) + 7) % 7)create_date_path(args, monday)return __date_fndef create_date_path(args, day):path = '/home/cheery/blog/www/entries/{}/{}/{}'.format(day.year, months[day.month-1], day.day)if args.create:try:os.makedirs(path)except OSError as exc:if not (exc.errno == errno.EEXIST and os.path.isdir(path)):raiseprint pathmonths = ['jan', 'feb', 'mar', 'apr', 'may', 'jun','jul', 'aug', 'sep', 'oct', 'nov', 'dec']if __name__=='__main__':main()
The update process of the website
Now we get to the main course.
Next we'll go through the update.py -script.
We'll check out how it is structured and what does it do.
from markdown2 import markdownfrom bs4 import BeautifulSoup, Tagimport datetime, osimport shutilimport subprocessimport retoday = datetime.date.today()now_utc = datetime.datetime.utcnow().strftime("%a, %d %b %Y %H:%M:%S GMT")
The today/now_utc contains datetime.date(2020, 8, 28),
'Fri, 28 Aug 2020 09:43:37 GMT', depending on the day.
def datepath(date):return date.strftime('%Y/%b/%d').lower()def datepath_to_iso(datepath):return datetime.datetime.strptime(datepath, '%Y/%b/%d') .date().isoformat()
The datepath converts the date object into a date path,
eg. '2020/aug/28', the datepath_to_iso converts this string back
into an unix date string: '2020-08-28'.
Next we have a Post -record,
I had already abandoned object oriented programming
when I started this blog,
therefore the script itself has remained
relatively maintainable and easy to explain.
It's a path,name,uri,date -record.
.pathis a path string..nameis the2020/aug/28/lolpost, eg. "name"..uriis the URL of the post. Eg./entries/2020/aug/28/lolpost..dateis the date tag for the post, the ISO-formatted string, eg. '2020-08-28'.
We have a way to construct all Post records from the fields.
class Post(object):def __init__(self, path, name, uri, date):self.path = pathself.name = nameself.uri = uriself.date = datedef __repr__(self):return self.pathdef all_entries(entries):for path, dirs, files in os.walk(entries):name = os.path.relpath(path, entries)if name.count('/') == 3:uri = os.path.join('/entries', name)date = datepath_to_iso(os.path.dirname(name))yield Post(path, name, uri, date)def all_unpublished(unpublished):for name in os.listdir(unpublished):path = os.path.join(unpublished, name)uri = os.path.join('/unpublished', name)date = datepath_to_iso(datepath(today))yield Post(path, name, uri, date)
Here's a way to convert the .md into a beautiful soup.
Then we have bit of a way to make anything into a beautiful soup.
And when the soup doesn't taste well, we have a way to dump it.
def markdown_soup(path):with open(path) as fd:soup = BeautifulSoup(markdown(fd.read()), "lxml")return soup.body.contentsdef soup(path, *args, **kw):with open(path) as fd:return BeautifulSoup(fd, *args, **kw)def dump_soup(path, soup):with open(path, 'w') as fd:fd.write(unicode(soup).encode('utf-8'))
Next comes the configuration. We also got the blog sitemap write starting up here. Then we get a list of all the entries and unpublished posts.
domain = 'https://boxbase.org'site_template = 'template.html'unpublished = 'www/unpublished'entries = 'www/entries'root = 'www'postname = 'what-is-this'entry = os.path.join(entries, datepath(today), postname)blog_sitemap = open('www/blog_sitemap.txt', 'w')blog_sitemap.write(domain + u"/".encode('utf-8') + "\n")#soup = BeautifulSoup(open("template.html"))posts = list(all_entries(entries))unpublished_posts = list(all_unpublished(unpublished))
The get_uri is a misnomer, it retrieves the URL of the post, based on index.
This is used to update the prev/next -links on the websites.
The set_uri finds a link named "prev" or "next" in the whole post and renames it.
All the post entries are sorted in by date later on.
def get_uri(index):if 0 <= index < len(posts):return posts[index].uridef set_uri(html, href, uri):for node in html.find_all(href=href):if uri is None:del node['href']else:node['href'] = uriposts.sort(key=lambda post: post.date)
The pre_blocks are reformatted.
Each line is converted into a <code> -block
and receives a line number through CSS-styling.
def format_pre_blocks(html, element):for pre in element.find_all("pre"):text = pre.text.rstrip("\n ")pre.clear()code = html.new_tag('code')pre.append(code)for line in re.split(r"(\n)", text):if line.isspace():code.append(line)code = html.new_tag('code')pre.append(code)else:code.append(line)
At this point all published posts are formatted and a HTML is generated for them.
# All published postsfor i, post in enumerate(posts):index_path = os.path.join(post.path, 'index.md')html_path = os.path.join(post.path, 'index.html')html = soup(site_template, 'lxml')html.article.contents = markdown_soup(index_path)set_uri(html, 'prev', get_uri(i-1))set_uri(html, 'next', get_uri(i+1))post.title = title = html.article.h1.stringhtml.title.string += ": " + titleformat_pre_blocks(html, html.article)dump_soup(html_path, html)# Add into sitemap. This is rudimentary measure.if isinstance(post.uri, unicode):blog_sitemap.write(domain + post.uri.encode('utf-8') + "\n")else:blog_sitemap.write(domain + post.uri + "\n")
The unpublished posts have their own setup.
# Rebuild all unpublished posts separately, they require# bit different handling.for post in unpublished_posts:index_path = os.path.join(post.path, 'index.md')html_path = os.path.join(post.path, 'index.html')html = soup(site_template, 'lxml')html.article.contents = markdown_soup(index_path)set_uri(html, 'prev', get_uri(len(posts)-1))set_uri(html, 'next', None)if html.article.h1:post.title = title = html.article.h1.stringhtml.title.string += ": " + titleformat_pre_blocks(html, html.article)dump_soup(html_path, html)
The main site is built, A header is added and navigation is dumped to the front with all the posts dumped along with a simple date tag.
#os.makedirs(entry)html = soup(site_template, 'lxml')footer = html.footerhtml.body.article.clear()h1 = html.new_tag('h1')h1.string = "Boxbase - Index"html.body.article.append(h1)html.body.find("nav", {'id':'article-nav'}).extract()#nav = html.new_tag('nav')#html.body.article.append(nav)table = html.new_tag('table')html.body.article.append(table)for post in reversed(posts):link = html.new_tag('a')link['href'] = post.urilink.string = post.titlerow = html.new_tag('tr')col = html.new_tag('td')date = html.new_tag('time')date.string = post.datecol.append(date)row.append(col)col = html.new_tag('td')col.append(link)row.append(col)table.append(row)#html.body.append(footer)dump_soup(os.path.join(root, 'index.html'), html)
The RSS is written down in a similar way as the index was written, except that only about 10 posts are listed.
xml = soup('template.rss', 'xml')xml.link.string = domain + '/'lbd = xml.new_tag('lastBuildDate')lbd.string = now_utcxml.channel.append(lbd)pd = xml.new_tag('pubDate')pd.string = now_utcxml.channel.append(pd)for post in reversed(posts[-10:]):item = xml.new_tag('item')title = xml.new_tag('title')title.string = post.titlelink = xml.new_tag('link')link.string = domain + post.uriguid = xml.new_tag('guid')guid['isPermaLink'] = 'true'guid.string = domain + post.uripd = xml.new_tag('pubDate')pd.string = datetime.datetime.strptime(post.date, "%Y-%m-%d").strftime("%a, %d %b %Y %H:%M:%S GMT")item.append(title)item.append(link)if os.path.exists(os.path.join(post.path, "summary")):with open(os.path.join(post.path, "summary"), "r") as fd:desc = xml.new_tag('description')desc.string = (fd.read().replace("\n", " ").strip()).decode('utf-8')assert "\r" not in desc.string, "summary must be unix-formatted utf-8 plaintext file."item.append(desc)item.append(guid)item.append(pd)xml.channel.append(item)dump_soup(os.path.join(root, 'feed.rss'), xml)
Finally the I run the RSYNC via SSH. Oh and the sitemap is being completed by closing the file handle.
def upload(src):dst = 'lol@boxbase:'+srcif os.path.isdir(src):src += '/'subprocess.call(['rsync', '-r', '--delete', src, dst])# The sitemap has been completed at this point.blog_sitemap.close()upload(os.path.join(root, 'index.html'))upload(os.path.join(root, 'blog_sitemap.txt'))upload(os.path.join(root, 'feed.rss'))upload(os.path.join(root, 'style'))upload(os.path.join(root, 'catalog'))#upload(os.path.join(root, 'lib'))upload(unpublished)upload(entries)
That's it. 🌼 It's Done!
Conclusion
This is a very primitive webblog, and possibly it could be worthwhile for me to just rewrite this system in Haskell and find something to replace the beautifulsoup.
However if somebody has already written a blog engine that has a similar structure and design, I could as well use that one. I think additionally I would just like about the:
- Structured sitemap as described.
- Table of contents to each post.
- Maybe I'd like to expose the source-syntax of the page, so it's easier for people to update and reuse the post contents. (If you use the content, remember to treat it with respect toward the author and properly attribute it to the origin like you always should.)
- Dependency tracking so that the website does not face redundant updates where they are not needed.
- Some built-in preview system so that I don't need to "Makefile" as much.
- Math notation, preferably with formal logic package.
Also, if you have ideas on what I should have listed above, feel free to inform me through any channel you prefer to use.
2020-08-30: I just saw this short ten-minute typography guide from the practical typography website. I've used this guide to improve my website before. I leave it here so that I remember to look into this next time.