From open deduction into interaction nets
Normalisation of the system I explored last week would seem to require that the constructs are transformed into interaction nets, computed there and then transformed back.
I understood how to make the interaction combinators after examining the lambdascope program and papre. Each node in the net has a principal port that is active while the other ports are passive.
You can implement an interaction net by describing a general notion of a node connected into other nodes by ports. Commute/annihilate procedures implement most of the interaction you need to make it to work.
Algorithm
I figured out a way to convert the deep-inference structures described in the previous post into interaction combinators.
An inductive algorithm can be discovered by looking for base cases: Simple sub-problems or special cases that are easy to solve.
In our abstract syntax, we can build structures that do not contain any proofs in them. They are plain propositions.
For every proposition we have a construct
that takes the proposition and returns it.
(λx.x):∀a:U. a -> a See? We even got a formal proof that states this!
So we can interpret plain propositions as proofs by marking the antecedent and succedent, then provide a trivial program. In interaction nets such program is a plain wire.
From the simple conversion we may be motivated to try whether
we can return an antecedent and a succedent for proof structures
such as (a p; b).
If the rule is primitive and clearly stated, it's simple to just match the rule to a pattern and build a corresponding interaction.
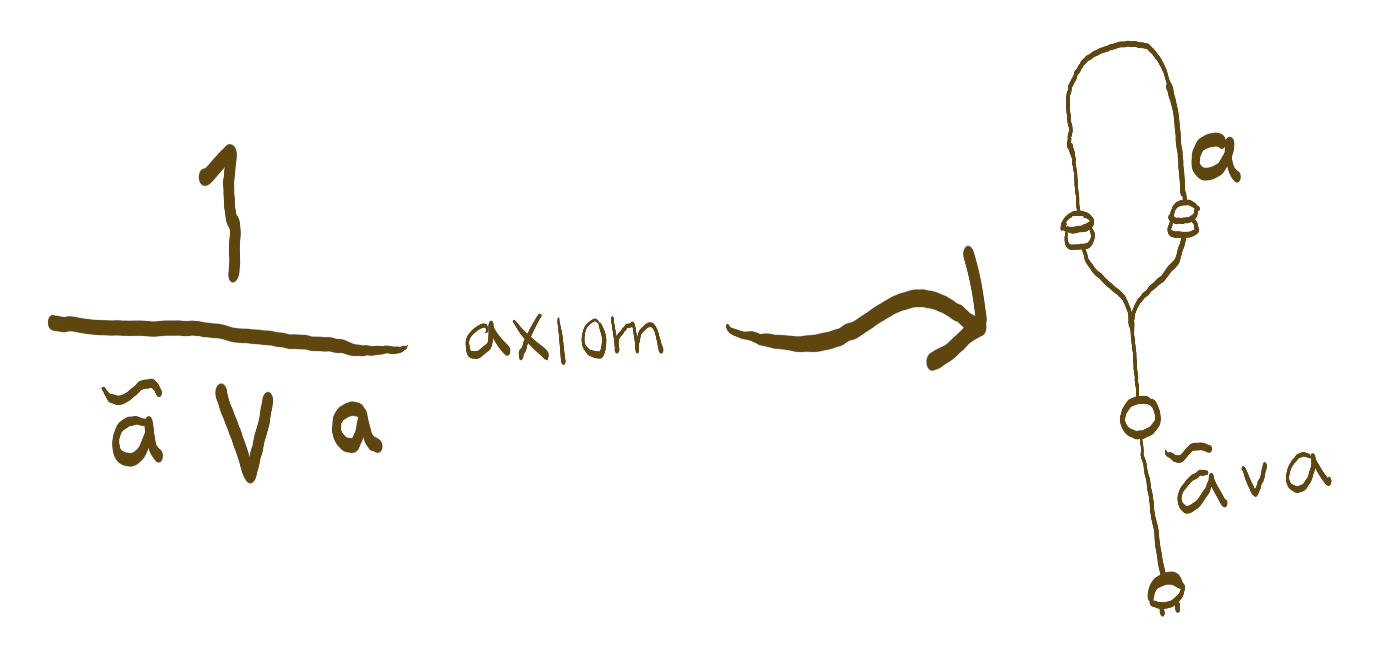
Finally we only have to solve how we build proofs from
propositions that contain proofs.
Eg. what to give for (a;b)∧(c;d).
We may approach this by constructing a function
(a -o b) -o (c -o d) -o (a∧b -o c∧d) with the interaction nets.
If you're not sure how to construct them, an automated theorem prover can supply most of these programs. You can feed in the following into the llprover to figure out how to produce the interaction net for the conjunction.
(a -> b) -> (c -> d) -> ((a*c) -> (b*d))There's a bit of a problem with the inversion rule.
(a -o b) -o (~a -o ~b)It's more clear if we attempt to prove it by hand.
----- ??? ∨ ------- ???a ∨ a ~b ∨ ~b------------------- a∨b ≡ b∨aa ∨ ~b ∨ a ∨ ~b------------------- a ≡ ~~a~~a ∨ ~b ∨ ~~a ∨ ~b---------------------- remove parentheses~(~a ∨ b) ∨ (~~a ∨ ~b)
We have to acknowledge that the negation here causes a little flip.
(a -o b) -o (~b -o ~a)We could also just rewrite the negation away before doing this, using the exact same rule, but... what's the point? We can solve it directly without much fuss.
Unfortunately our proofs are going to end up being humongous if we can only rely on explicitly denoted rules. The real challenge here is to ensure that we can deduce the composition of trivial proofs being used.
For example, with the structure rule we'd be often applying the following equations:
a∧(b∨c) → (a∧b)∨c, a∧b → b∧a, a∧(b∧c) ≡ (a∧b)∧cWe could perhaps group these and then have them applied automatically when we type something like:
a∧(b∨f)∧(c∨e)------------- s*a∧b∧c∨e∨f
To check whether the above rule follows from the earlier simple rules seem to be a lot like the word problem, that could be perhaps solved by Knuth-Bendix. Probably not because the word-problem seem to solve whether two things are the same under some set of rules, not the problem whether one thing implies another.
That, or then we can examine how we'd solve that with the theorem prover. Flip the antecedent to the bottom first!
a∧(b∨f)∧(c∨e)------------- s* ------> a∧(b∨f)∧(c∨e) -o (a∧b∧c)∨e∨fa∧b∧c∨e∨f
It'd be (a*(b+f)*(c+e)) -> (a*b*c)+e+f in llprover's syntax.
Automated theorem proving is a whole field, and it seems we can use it to add bit of convenience into programming.
Btw.... We've been proving things about an algebra here as if it was just yet an another run at the toilet. Maybe that's the idea behind the identity type and we could construct it through bi-implication in our system.
Gotta go reverse as well
Having your proofs being reduced isn't much fun if they're in a foreign language after the operation.
I'm not sure how to proceed with this yet, but it's clear that interaction nets can be interpreted as proofs. Every node has a simple meaning with few variations of how it contributes to the shape of the corresponding proof.
It might be simple as building the whole proof from top to bottom, then plug the top with a theorem prover (again), but it takes some studying to confirm that this is so easy.
Remaining problems with quantifiers
I'm still staying afar from the quantifiers for now. They're a difficult subject I have no hope of implementing until I have other things sorted out somehow at least once.
The quantification rules are looking like the following in linear logic:
∀x:Bool.P x----------- [x/y]P yP y----------- [x/y]∃x:Bool.P x
If you think of the quantification as application then you'd think the 'y' gets duplicated all over the place here and we're not doing linear logic anymore.
But if you think of quantification as holes for values to fill, then this is a bit simpler. To obtain multiple equivalent instances in the required type, feed them into the locations where they're demanded.
∀x:Bool.P x x------------- [x/true]P true true
Still doing this doesn't solve everything because
we're implying that true ≃ true here.
I haven't demonstrated that I can implement the identity type in this system.
So...?
It seems implementation of this kind of a language is going to be feasible. We can implement such language, we can make it blazing fast and complete the rest of the properties it needs to function as a theorem prover, I can perhaps even implement the dialogic logic programming on top of it... Then what?
It'd be a formal system on founded on rules that describe interactions. It'd also be a programming environment founded on representations of logic, rather than the another way around. Some programs created by the system could be compiled to efficient programs that run without dynamic memory allocation. Also, I think the language itself is very easy to understand.
For example, the monads are representable with two expressions: 'unit' and 'bind'. What do they look like in this system?
The types annotated to them usually are:
unit :: a -> M abind :: M a -> (a -> M b) -> M b
Unit is required to be an identity in some sense, and bind must be associative. I don't intend to explain these concepts in full, just enough that you can compare them a little bit.
Monads can provide fmap.
It's the idea that we can upgrade a function to apply into the monad.
Here's the type and the proof that we can do so:
fmap :: (a -> b) -> M a -> M afmap f m = bind m (x ↦ unit (f x))
The deep inference equivalents are:
a--- unitM aM a ∧ (~a ∨ M b)---------------- bindM bM a ∧ (~a ∨ b)-------------- fmapM b
The proof for fmap would look like this:
bM a ∧ (~a ∨ --- unit)M b--------------------- bindM b
Now these seem a bit complicated, but note these constructs are raw.
The fmap looks a bit like the conjunction earlier on.
This means that we could use the deep-inference syntax with our monads:
aM (--- f)b
The unit means that we don't need to reason
whether we got the monad from somewhere,
we can assume that we can always get M 1 -monad from somewhere.
The bind means that we'd have the following rule available as well:
(M a) ∧ b---------M (a ∧ b)
Haskell provides special syntax for handling monads. I don't know if it'd be necessary because this language wouldn't require monads to represent interactions, but we could have perhaps:
stringIO (====== putStrLn)1
Similarly we could use them to represent tasks that "ladder" down if the previous task succeeds.
1====================== brew_coffeecoffeeMaybe ====================== get_milkcoffee ∧ milk====================== get_cheesecoffee ∧ milk ∧ cheese--------------------------------------------------------- ~maybe1 ⊔ coffee ⊔ coffee ∧ milk ⊔ coffee ∧ milk ∧ cheese------ :/ ------------- :\ ---------------------- :)
Note there are bit of complications here, the thing is, we can't get rid of things unless we have an obvious way to do so.
The language would be perfect for presenting computer graphics rendering, musical composition or sound synthesis. Everything doesn't need to be immutables, stay same all the time, stay available the whole time to be convenient to handle in the program.